Peter’s Blog Roll
A lot of cool people with lots of cool content are on Peter Rukavina’s blog roll!
On Twitter
I have been using twitter on and off for quite a while now. In fact, a few days ago was my 13th twitter anniversary. This means I am in puberty, and I have a few thoughts!

I do have problems:
- It’s too much! Besides all my other work, there is no chance I can read my entire timeline every day anymore. But if I can not do this – what’s the point? Who has the same problem? Is nobody reading the entire timeline on a daily basis?
- I could get rid of a few subscriptions (unfollow more often, follow less often). Fair enough. But what if I want to filter… say I want to read the posts of only a subset of friends? Ok, I could do lists. But then the ones I read in a list do still show up in my timeline (don’t they?). There is no “marked as read”, is there? Also, I might not see posts of all the participants in a list every day, i.e. I don’t like static lists but rather dynamic filters. Also lists seem not to be a core feature of twitter that developers spend a lot of time on.
- Threaded tweets? Really? If you have things to say that don’t fit into 140 (or whatever the current limit might be) characters – write a blog post! It’s also easier to read, despite Twitterrific’s recent improvements for composing and reading threaded tweets.
- Generally, the direct feedback of likes and retweets is a key advantage of twitter (granted, there are option for implementing similar things for blog posts, “webmentions”, explained by Peter Rukavina and by Brett Terpstra). The functionality of direct feedback is largely broken for third party Twitter clients.
- Speaking of blog posts: All in all, RSS seems like a much better solution to me. However, unfortunately, not many people are using it, it seems to me (there are some exciting new open source activities). Maybe this is a sign for me being old, but RSS facilitates way better sorting, both by author and by time. it’s much easier discernible what I have read before and what not. Granted, posting on a blog is a bit more involved (a few steps more) than posting to twitter, but isn’t it much better? There are also more open
- There are problems. I haven’t had any related to bad interactions / trolls. But great also have problems, for example Emily Hunt, or DrDrang
@drdrang: Don’t want to make a big deal about this, but I assume some of you will want to know. Casey Newton’s recent articles about content moderators have made me question whether I want to have anything to do with any social media. (1/2)
Solutions?
I’m curious how other people see this! Maybe you can offer suggestions on how to circumvent this.
- I’ve started playing with more open alternatives to twitter (@planetwater on micro.blog), but it seems like there is not yet sufficient critical mass. This has the advantage that we own our content.
- However, I feel like the real question is this: What is the best content for twitter?
- let’s look at two successful twitter accounts that I subscribe to
- @LaurelCoons posts multiple times per day a few key facts on various topics
- @Muschelschloss posts multiple times per day on news related (“faster than Reuters”)
- @WaterWired posts mostly what he calls “Water Daily” summary posts on water-related issues/news in a certain region (of the US)
- I have a really hard time posting every day let alone multiple times per day every day. Also I am not sure if this lends itself well for science / science communication
- I follow a reasonable number of researchers and scientists who once in a while post really interesting things. And I would put myself in this category. I do see that these posts get lost in the noise (see above… too much…)
- Twitter seems like a good place for scientific job / MSc / PhD postings and announcements. On aggregator accounts, but also on accounts of individual researchers. This is useful, but twitter is not the only option for such announcements.
- let’s look at two successful twitter accounts that I subscribe to
- Tools: I use twitter online and twitterific on macOS and iOS. Are there better tools than that?
The key question that remains for me: How do I get from nice quick interactions, pointers to webpages and books (that are really useful) to more substantial things? I will think about this and maybe some of you have some thoughts – I’d appreciate it!
Climate Catastrophe Across Europe Including Venice
Nothing could give us a visual reminder of what happens when the sea rises than the city of Venice. It has experienced the highest tides in Venice in 50 years, which is putting the entire town at risk. And yet, politicians are dragging their feet and lining their pockets.
from: Om Malik: “Venice and Climate Change“
Catastrophic Weather around the Mediterranean. The biggest flood in Venice since the 60’s caused the largest publicity, but also other severe events
There are multiple lines of evidence:
- a deterring Video on Venice,
- an equally (more?) deterring video from town in Sicily,
- massive amounts of snow together with closed roads (including Brenner)
- avalanches,
- torrential Rain in Rome,
- generally dangerous situations in Italy.
The Washington Post reports in “Venice floods threaten priceless artwork and history — and a unique way of life”:
Flooding in Venice is not merely an inexpensive inconvenience. Named a UNESCO World Heritage Site in 1987, Venice is home to priceless works of art by such Italian Renaissance masters as Tintoretto, Giorgione and Titian; historic basilicas; and a unique way of lagoon-based metropolitan living for about 50,000 residents. According to experts, it’s also a sobering preview of how climate change, accelerated by human behavior, will not just complicate Venetians’ unique and fragile way of life but wash it away entirely.
and a quote from Michael Oppenheimer:
The threat is if Venice becomes uninhabitable by normal humans beings. One of the great things about Venice is that real people live there and go about their daily business
(Venice also hosts many old texts in the Biblioteca Marciana)
The German weather service (DWD) explains the meteorological cause for this havoc in many parts of Europe: relatively stationary conditions of a high pressure in eastern Europe, and low pressure over France. This leads to cold air with polar origins being drawn into western Europe at the western side of the low pressure system, take up moisture over the still relatively warm Mediterranean Sea, and are being moved northwards, against the Alps on the western side of the high pressure system.
The jet stream, as discussed by Stefan Rahmsdorf, tells the same story: southward movement of air west of the UK, movement across the warm Mediterranean Sea, and northward movement over Italy.

But, not only in Europe: No rain together with fires in Australia.
Water Risk Atlas
The Water Resources Institute released their “Water Risk Atlas“.

A German and an US newspaper have recently posted their perspectives:
- In Europa wird das Wasser knapp, Süddeutsche Zeitung: Two federal states (Hessen and Brandenburg) suffer from water quantity issues
- Mapping the Strain on Our Water, Washington Post: Many places in Asia have water-related issues, particularly India and China.
Water in the News
Water in the News
Here are four recent articles (three in German) about water-related issues:
- “Wir verlieren unwiderruflich die besten Böden”, Süddeutsche über Wasser-Quantitätsprobleme, Landwirtschaft und Plastik in Südspanien
- “As a major Indian city runs out of water, 9 million people pray for rain”; the Washington Post about lack of water in India
- “Überdüngung geht weiter“, TAZ über geplante Regulierung der Nitrat-Ausbringung in der Landwirtschaft
- “Wem gehört das Wasser”, Süddeutsche Zeitung über Effekte des Klimawandels auf die Trinkwasserversorgung (in Franken)
What are Random Numbers?
I did a wonderful #statistics experiment with students in stats class the other day on random numbers:
I divided the class into two groups. I gave a coin to one group and told them to flip this coin 20 times and record the resulting sequence of heads and tails. I asked the other group to come up with sequence of heads and tails in their heads and record the best sequence they can come up with. I told them I would leave the room and come back after five minutes, look at both sequences, and tell them which was created by the coin and which one in the heads of the other group.
These are the two sequences they came up with
HTTTTHHTHHHHTTHHHHTTand
HTHTHTHTHTHTTHTHTTTH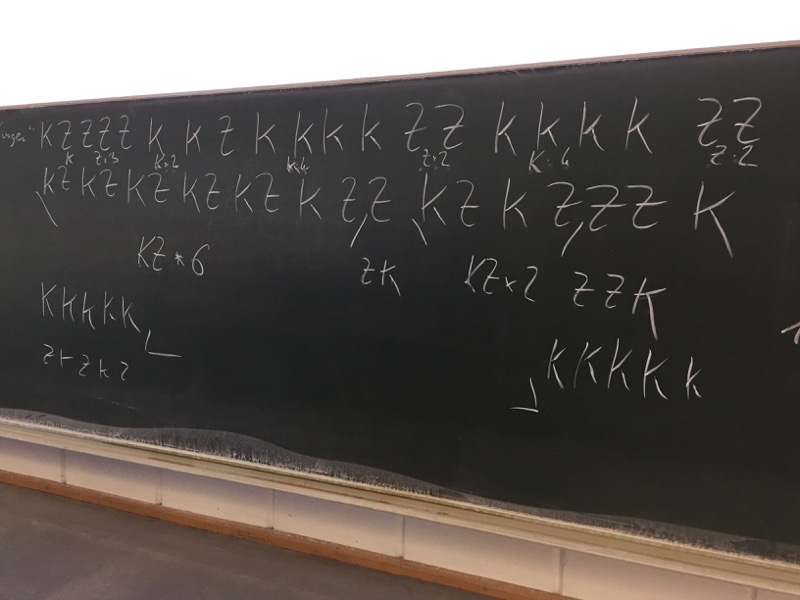
Can you guess which sequence was constructed by what group?
Here is some background:
- Nice explanation using Markov Chains by Paul Ginsparg
- I had borrowed the idea from Ilya Perederiy, and especially from this vido by “numberfile” linked to on Ilya’s blog
- the post “Randomness: The Ghost In The Machine?” raises a few interesting philosophical questions, such as why Lady Justice, is usually both carrying sword/scales and is blindfolded, hence including an element of randomness to her. There is also some historical context, such as sometimes political leaders have been chose through random processes: “in Renaissance Venice, the doge was chosen by sortition — a type of lottery”, which a process that this wikipedia article confirms.
ssh fun
I have setup a raspberry pi as a measurement computer. Now I can access it
a) on my Mac by mounting a directory, using SSHFS 2.5.0 via
sshfs -o volname="<MOUNT_NAME>" <USER>@<IP_ADRESS>:<directory_on_raspberry> <directory_on_my_mac>b) on my iPad! I use OpenTerm to ssh into the machine, run scripts, and I use ShellFish (currently in beta) to basically mount the directory with the output into the file system (I mean into the Files App) on my iPad.
Whoooopeee!!
Starting a New Blog
I had linked to a post by Peter Rukvina’s last time. I am doing it again – this time he linked to Rosie, who started a blog in 2019 called “press pound”.
I can’t applaud Peter’s comment enough:
I’m happy to see the corner turn from “why did blogging die when we loved it so?” to “I’m going to start a new blog!”
Moving to Personal
Since I while I have a new job at the Research Facility for Subsurface Remediation (VEGAS) at the University of Stuttgart (link to newly setup webpage and twitter presence). I’ve been thinking about it for a while and came to the conclusion that both this blog and the associated planetwater twitter presence will move to more private conversations, although still associated to water.
As a first, I want to give a shout out to Peter Rukvina at ruk.ca. There is a lot of talk about a renaissance about the open web. A renaissance of RSS. A renaissance of blogging. Peter has been there since before I started to be there — and he is still there, stronger than ever! His recent post, My Own Private Underhay, is an orbitruary on surface. Really, he is laying out his way of life. He boils it down to this:
What I have started to do, in my daily life, is that when I’m faced with small forks in my road–take the car or take the bike? watch TV or join a committee? have a nap or call my mother? order pizza or learn to make pizza? –- I will take the fork that, while it might be a little harder, require a little more effort, might take me out of the realm of things I’m comfortable doing, is the fork that’s best for my family, my community, and the planet.
I encourage everyone to go to Peter’s site and check out his humanitarian- printing- open- (source) and overall kind- ness!
Ein Regengenerator der anderen Art… nicht multi-site und nicht vektor-autoregressiv, aber trotzdem schön… 🙂 https://rainbowhunt.me
